This was 2024 for me.We are approaching the end of 2024 — a good moment to reflect on a year full of personal milestones and significant developments in the…Dec 26, 2024Dec 26, 2024
Mastering State in Stateless LLMsLarge Language Models (LLMs) operate without inherent memory — they are stateless by design. The only “state” they recognise is your…Dec 12, 2024Dec 12, 2024
Published inTowards DevElastic.ON Amsterdam 2024This week, I attended Elastic.ON in Amsterdam. I still remember the first few Elastic events with just a few people, then going to San…Nov 27, 2024Nov 27, 2024
The Evolution of Creativity: Thriving in the Age of AIIn a world where reaching the end goal is easy, the interest in the journey starts to fade. Creativity, like a journey, derives its…Oct 9, 2024Oct 9, 2024
Build an Agent using Amazon Bedrock.A widespread use of large language models (LLMs) is creating agents. An agent can reason, decide what to do, and use tools to take action…Sep 15, 2024Sep 15, 2024
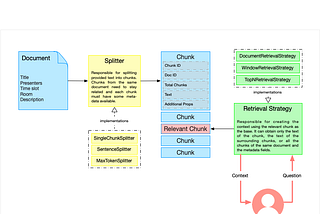
RAG: splitter chain for proper chunks.RAG, short for Retrieval Augmented Generation, is a popular pattern for working with Large Language Models. In previous blog posts, I…Aug 8, 2024Aug 8, 2024
What? A synonyms API for Elasticsearch?One often (over) used feature of lexical search is synonyms. If something does not work, we add a synonym. When used correctly, synonyms…Jul 11, 2024Jul 11, 2024
RAG optimisation: use an LLM to chunk your text semantically.In a previous blog post, I wrote about providing a suitable context for an LLM to answer questions using your content. The previous post…Jul 7, 20242Jul 7, 20242
Introducing Rag4p GUIYesterday was the first public appearance of my latest project, Rag4p-GUI. This project is a graphical interface for the Rag4p library. The…Jul 4, 2024Jul 4, 2024
Getting the proper context for RAG is choosing your chunking and retrieval strategy.You need a Large Language Model to answer questions about your content using only the content that you provide. This is where RAG or…May 21, 2024May 21, 2024